Reinforcement Learning in Item Recommendation
Usually, our application optimization problems are modeled as deep contextual bandit problems. This means that for a given state, an agent will select the action that optimizes the immediate reward. Unfortunately, this leads to near-sighted optimization, rather than optimization of the true objective. However, by using reinforcement learning (RL) we can optimize discounted sums of future rewards across the player’s lifetime.
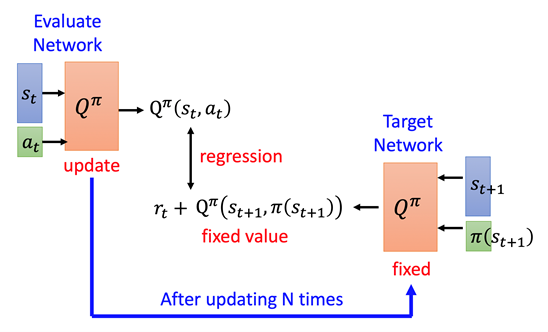
In order to accomplish long-sighted optimization, we introduce “Dueling DQN” to do the package/item recommendation. For the scenarios in the games we optimize, is the current user feature vector (UF), is the current item/package recommended, represented by an id. With DQN we are going to model the state and action sequence along an agent lifetime via and. The DQN agent will initiate action sequences that optimize the discounted sum of rewards which is called the (discounted) return. The DQN optimal Q-value function is defined recursively as. This will be defined as a loss function to be optimized by performing mean-squared error minimization through. With sampled from a replay pool (which in our case is a window over our rec log DB of N days). The reward for package recommendation in games specifically is; as such DQN would be maximizing the discounted LTV of a user’s package purchasing behavior.
We can also engineer the model to apply DQN to other scenarios in other games. At present, we have deployed this reinforcement learning model in two games.